Some opinions about socio-technical systems (December 2022)
Since this blog is my personal corner of the internet, I figured it was time to start filling it with my hot takes. Here, I’m going to list a scattered bunch of opinions I have, mostly about team interactions but I suspect we’ll touch on architecture choices as well.
My main reason for writing this is because I suspect that I am wrong about several of these opinions, and I’d welcome feedback on them at quail@cursedquail.com. The best case is that my opinions are just lacking some nuance, and that some helpful people explain the missing pieces :).
Warning: this post is a bit rambly, and is largely unedited. It’s a conversation starter, not a conversation ender.
The most important thing is the interface between teams
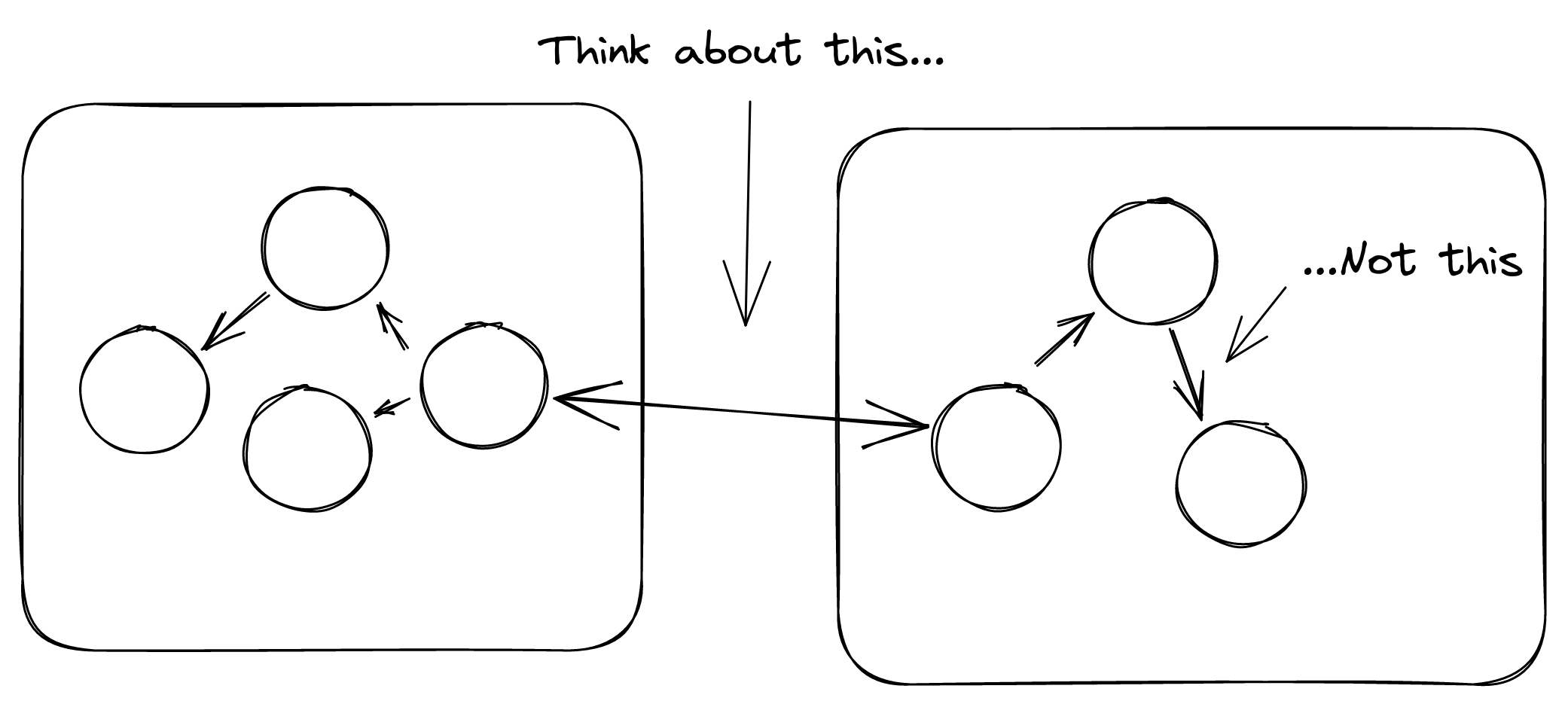
This is probably the opinion I feel the strongest about. Basically, when you’re dividing services between teams, or creating new associations between teams, you should care the most about what the interface between the various teams is.
“Interface” here doesn’t just mean things like API contracts, but also how the teams will contact each other. How are modifications proposed? How do teams make work happen in other teams?
The interface is important because it’s the hardest thing to change, because it requires agreement between two parties with conflicting priorities. Changing things within a team is exponentially easier than changing a thing shared between two teams. Therefore, if you’re going to create a relationship between two teams, you should really spend the most amount of time thinking about what the interface between them is. All other things are wholly owned by a single team and are theoretically easier to change.
A lot of my thinking here stems from my reading about Domain-Driven-Design (DDD), which has a whole taxonomy to describe the various kinds of relationships between teams. DDD has unfortunately lost a lot of meaning in recent years, but this taxonomy is genuinely useful.
Sometimes, it is better to have multiple rigid interfaces than one flexible one.
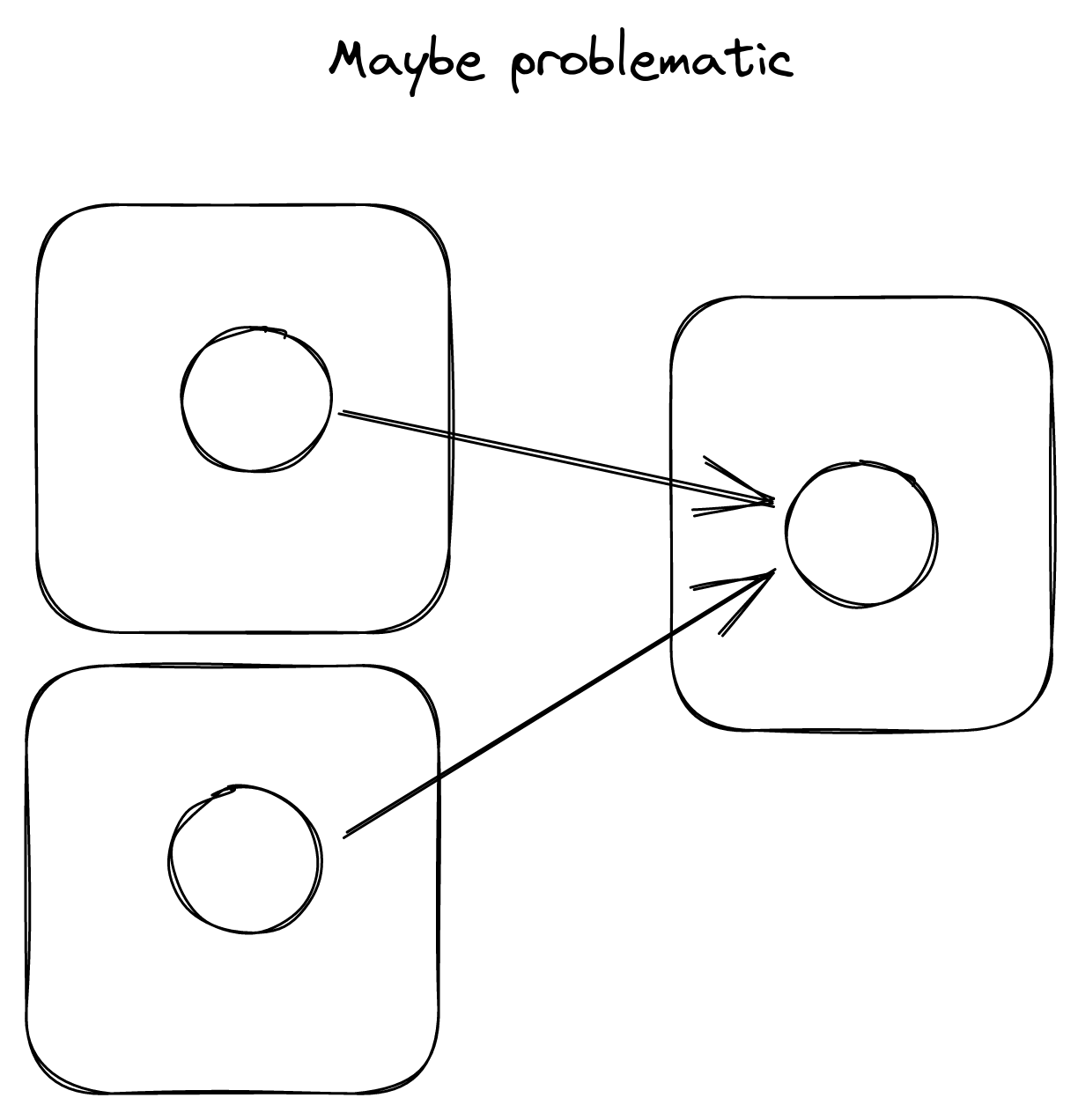
This one is much more situational. Basically, you and some other team have some shared interface, and another team would like to use it as well. When this is happening, it might be worth your time to give this new team a dedicated, separate interface. This becomes even more important if the needs of your two consuming teams will diverge at some point, and even more important if the two consuming teams don’t collaborate much.
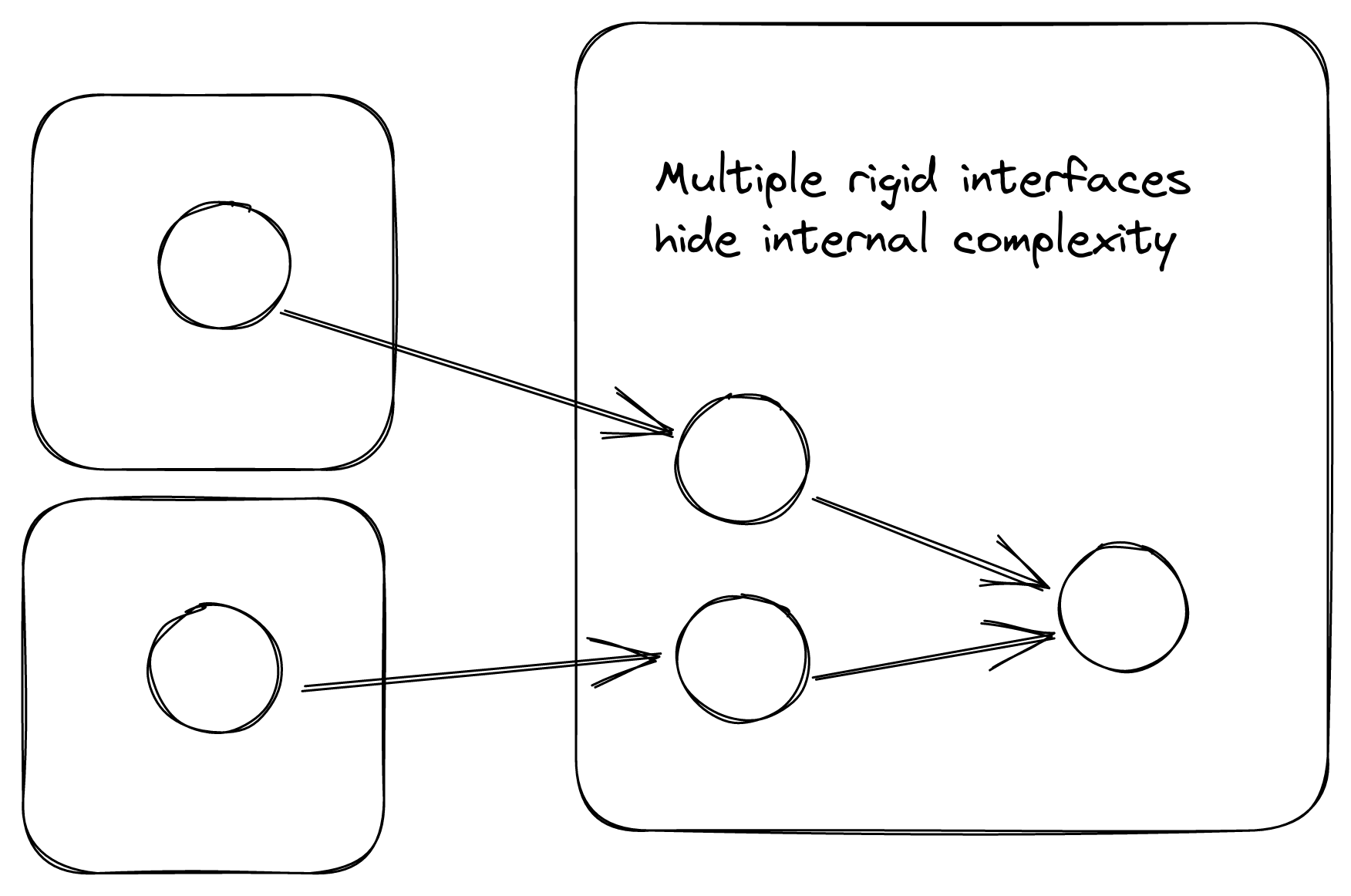
Something I’ve been working up to: if a flexible interface exists, it might be best to keep it hidden. Because lots of teams depend on this complex inner process, you want to be able to refactor and change it quickly. If you expose it, you might end up with yet-unknown teams simply using that flexible interface, stifling efforts at future change. Maybe this is good! Again, this opinion is very situational and very weakly held.
The trick to making the practice sustainable is to have that flexible internal interface that you can use. Done correctly, these new interfaces can be spun up in a day or two from zero to production, and the teams you collaborate with will appreciate having a dedicated interface to use. It can also lead to increased political capital in the organization, as your team becomes known as being able to quickly handle changing requirements from other teams. Win win win!
I’m intentionally not talking about the downsides of this approach. I think a lot of people have the reaction of exposing the ultra-flexible interface, and so I’m trying to combat that reaction. Obviously the pendulum can swing too far the other way: take this one with a grain of salt, and apply it with care: you’ll probably know when you need it.
The moving target of innovation
Oh boy this is probably my hottest take, and to be honest I wrote the above two in service of it. It’s also the one that I have the hardest time describing, so apologies if this makes zero sense.
In short: as organizations grow, innovation will happen on top of existing components, instead of within those components. Innovation here specifically refers to user-visible innovation, like new products or features.
When your organization begins, you probably have some core “secret sauce”, the thing that makes your business unique. In the beginning, you’ll pour all of your efforts on innovating inside of this secret sauce, adding new features and capabilities to it. However, your organization is going to grow, and it will grow to the point where you need multiple teams. In my opinion, it is inevitable that you will have a team dedicated to maintaining and scaling this core component. You can delay it for a long time with practices like “reverse conway maneuvers” and “stream-aligned teams”, but I believe it’s an inevitability: at some point, it’s just going to make the most sense and there’s nothing you can do to change that.
Note: I’m going to refer to this hypothetical team as the “core team”. This ignores that there will probably be multiple core teams, and even multiple layers of core teams as time goes on. It also makes the core team seem more important than the teams they support, which is a dangerous attitude that you should squash if it comes up.
Once you have a team dedicated to working on this “core component”, they’re going to be insulated away from the user-visible effects of their changes. Instead, you’re going to have new teams creating interfaces with this core team, in order to create innovations that delight your users. The core team will switch from creating new features wholesale, and go towards decomposing the various components they own and exposing them in a way that is easy for other teams to use.
If you do end up going down this path, please refrain temptation to fill it with all your best engineers: that’s just going to make them more imposing and make it harder for them to collaborate. Instead, treat it like any other team at your company, with a mix of junior and senior engineers, and even a product manager. My only advice is to keep it small: make it large enough to have a comfortable on-call rotation, and no larger.
Addendum 2023-01-11
Some additional thoughts after talking about this with a coworker. The reason for this is that the underlying service becomes commodified. To people building on top, it ends up being part of their infrastructure layer: a thing with some uptime that is close enough to 100% for you to not worry about it. For a good example of this, consider how you might treat S3: it just works, you put your data in, you get your data out. This makes problems in the “infrastructure” much worse, but it also means you can ship things faster.